
Machine Learning is a system that can learn from example through self-improvement and without being explicitly coded by programmer. The breakthrough comes with the idea that a machine can singularly learn from the data (i.e., example) to produce accurate results.
Machine learning combines data with statistical tools to predict an output. This output is then used by corporate to makes actionable insights. Machine learning is closely related to data mining and Bayesian predictive modeling. The machine receives data as input, use an algorithm to formulate answers.
A typical machine learning tasks are to provide a recommendation. For those who have a Netflix account, all recommendations of movies or series are based on the user’s historical data. Tech companies are using unsupervised learning to improve the user experience with personalizing recommendation.
Machine learning is also used for a variety of task like fraud detection, predictive maintenance, portfolio optimization, automatize task and so on.
How does Machine learning work?
Machine learning is the brain where all the learning takes place. The way the machine learns is similar to the human being. Humans learn from experience. The more we know, the more easily we can predict. By analogy, when we face an unknown situation, the likelihood of success is lower than the known situation. Machines are trained the same. To make an accurate prediction, the machine sees an example. When we give the machine a similar example, it can figure out the outcome. However, like a human, if its feed a previously unseen example, the machine has difficulties to predict.
The core objective of machine learning is the learning and inference. First of all, the machine learns through the discovery of patterns. This discovery is made thanks to the data. One crucial part of the data scientist is to choose carefully which data to provide to the machine. The list of attributes used to solve a problem is called a feature vector. You can think of a feature vector as a subset of data that is used to tackle a problem.
The machine uses some fancy algorithms to simplify the reality and transform this discovery into a model. Therefore, the learning stage is used to describe the data and summarize it into a model.
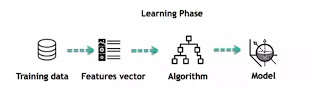
For instance, the machine is trying to understand the relationship between the wage of an individual and the likelihood to go to a fancy restaurant. It turns out the machine finds a positive relationship between wage and going to a high-end restaurant.
Inferring
When the model is built, it is possible to test how powerful it is on never-seen-before data. The new data are transformed into a features vector, go through the model and give a prediction. This is all the beautiful part of machine learning. There is no need to update the rules or train again the model. You can use the model previously trained to make inference on new data.
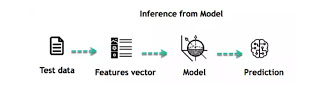
The life of Machine Learning programs is straightforward and can be summarized in the following points:
- Define a question
- Collect data
- Visualize data
- Train algorithm
- Test the Algorithm
- Collect feedback
- Refine the algorithm
- Loop 4-7 until the results are satisfying
- Use the model to make a prediction
Once the algorithm gets good at drawing the right conclusions, it applies that knowledge to new sets of data.
“Machine learning Algorithms and where they are used?”
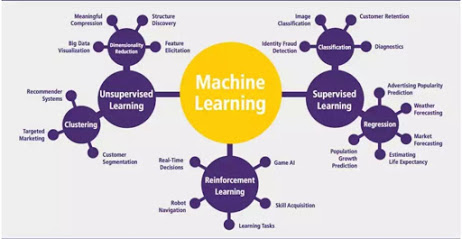
Machine learning can be grouped into two broad learning tasks: Supervised and Unsupervised. There are many other algorithms
Supervised learning
An algorithm uses training data and feedback from humans to learn the relationship of given inputs to a given output. For instance, a practitioner can use marketing expense and weather forecast as input data to predict the sales of cans.
You can use supervised learning when the output data is known. The algorithm will predict new data.
There are two categories of supervised learning:
- Classification task
- Regression task
Classification
Imagine you want to predict the gender of a customer for a commercial. You will start gathering data on the height, weight, job, salary, purchasing basket, etc. from your customer database. You know the gender of each of your customer, it can only be male or female. The objective of the classifier will be to assign a probability of being a male or a female (i.e., the label) based on the information (i.e., features you have collected). When the model learned how to recognize male or female, you can use new data to make a prediction. For instance, you just got new information from an unknown customer, and you want to know if it is a male or female. If the classifier predicts male = 70%, it means the algorithm is sure at 70% that this customer is a male, and 30% it is a female.
The label can be of two or more classes. The above example has only two classes, but if a classifier needs to predict object, it has dozens of classes (e.g., glass, table, shoes, etc. each object represents a class)
Regression
When the output is a continuous value, the task is a regression. For instance, a financial analyst may need to forecast the value of a stock based on a range of feature like equity, previous stock performances, macroeconomics index. The system will be trained to estimate the price of the stocks with the lowest possible error.
| Algorithm Name | Description | Type |
| Linear regression | Finds a way to correlate each feature to the output to help predict future values. | Regression |
| Logistic regression | Extension of linear regression that’s used for classification tasks. The output variable 3is binary (e.g., only black or white) rather than continuous (e.g., an infinite list of potential colors) | Classification |
| Decision tree | Highly interpretable classification or regression model that splits data-feature values into branches at decision nodes (e.g., if a feature is a color, each possible color becomes a new branch) until a final decision output is made | Regression Classification |
| Naive Bayes | The Bayesian method is a classification method that makes use of the Bayesian theorem. The theorem updates the prior knowledge of an event with the independent probability of each feature that can affect the event. | Regression Classification |
| Support vector machine | Support Vector Machine, or SVM, is typically used for the classification task. SVM algorithm finds a hyperplane that optimally divided the classes. It is best used with a non-linear solver. | Regression (not very common) Classification |
| Random forest | The algorithm is built upon a decision tree to improve the accuracy drastically. Random forest generates many times simple decision trees and uses the ‘majority vote’ method to decide on which label to return. For the classification task, the final prediction will be the one with the most vote; while for the regression task, the average prediction of all the trees is the final prediction. | Regression Classification |
| AdaBoost | Classification or regression technique that uses a multitude of models to come up with a decision but weighs them based on their accuracy in predicting the outcome | Regression Classification |
| Gradient-boosting trees | Gradient-boosting trees is a state-of-the-art classification/regression technique. It is focusing on the error committed by the previous trees and tries to correct it. | Regression Classification |
Unsupervised learning
In unsupervised learning, an algorithm explores input data without being given an explicit output variable (e.g., explores customer demographic data to identify patterns)
You can use it when you do not know how to classify the data, and you want the algorithm to find patterns and classify the data for you
| Algorithm | Description | Type |
| K-means clustering | Puts data into some groups (k) that each contains data with similar characteristics (as determined by the model, not in advance by humans) | Clustering |
| Gaussian mixture model | A generalization of k-means clustering that provides more flexibility in the size and shape of groups (clusters | Clustering |
| Hierarchical clustering | Splits clusters along a hierarchical tree to form a classification system.Can be used for Cluster loyalty-card customer | Clustering |
| Recommender system | Help to define the relevant data for making a recommendation. | Clustering |
| PCA/T-SNE | Mostly used to decrease the dimensionality of the data. The algorithms reduce the number of features to 3 or 4 vectors with the highest variances. |
“How to choose Machine Learning Algorithm”
There are plenty of machine learning algorithms. The choice of the algorithm is based on the objective.
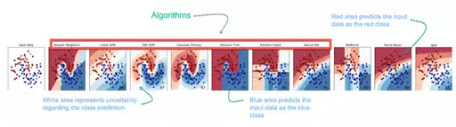
In the example below, the task is to predict the type of flower among the three varieties. The predictions are based on the length and the width of the petal. The picture depicts the results of ten different algorithms. The picture on the top left is the dataset. The data is classified into three categories: red, light blue and dark blue. There are some groupings. For instance, from the second image, everything in the upper left belongs to the red category, in the middle part, there is a mixture of uncertainty and light blue while the bottom corresponds to the dark category. The other images show different algorithms and how they try to classified the data.
Challenges and Limitations of Machine learning
The primary challenge of machine learning is the lack of data or the diversity in the dataset. A machine cannot learn if there is no data available. Besides, a dataset with a lack of diversity gives the machine a hard time. A machine needs to have heterogeneity to learn meaningful insight. It is rare that an algorithm can extract information when there are no or few variations. It is recommended to have at least 20 observations per group to help the machine learn. This constraint leads to poor evaluation and prediction.
Application of Machine learning
Augmentation:
- Machine learning, which assists humans with their day-to-day tasks, personally or commercially without having complete control of the output. Such machine learning is used in different ways such as Virtual Assistant, Data analysis, software solutions. The primary user is to reduce errors due to human bias.
Automation:
- Machine learning, which works entirely autonomously in any field without the need for any human intervention. For example, robots performing the essential process steps in manufacturing plants.
Finance Industry
- Machine learning is growing in popularity in the finance industry. Banks are mainly using ML to find patterns inside the data but also to prevent fraud.
Government organization
- The government makes use of ML to manage public safety and utilities. Take the example of China with the massive face recognition. The government uses Artificial intelligence to prevent jaywalker.
Healthcare industry
- Healthcare was one of the first industry to use machine learning with image detection.
Marketing
- Broad use of AI is done in marketing thanks to abundant access to data. Before the age of mass data, researchers develop advanced mathematical tools like Bayesian analysis to estimate the value of a customer. With the boom of data, marketing department relies on AI to optimize the customer relationship and marketing campaign.
Example of application of Machine Learning in Supply Chain
Machine learning gives terrific results for visual pattern recognition, opening up many potential applications in physical inspection and maintenance across the entire supply chain network.
Unsupervised learning can quickly search for comparable patterns in the diverse dataset. In turn, the machine can perform quality inspection throughout the logistics hub, shipment with damage and wear.
For instance, IBM’s Watson platform can determine shipping container damage. Watson combines visual and systems-based data to track, report and make recommendations in real-time.
In past year stock manager relies extensively on the primary method to evaluate and forecast the inventory. When combining big data and machine learning, better forecasting techniques have been implemented (an improvement of 20 to 30 % over traditional forecasting tools). In term of sales, it means an increase of 2 to 3 % due to the potential reduction in inventory costs.
Example of Machine Learning Google Car
For example, everybody knows the Google car. The car is full of lasers on the roof which are telling it where it is regarding the surrounding area. It has radar in the front, which is informing the car of the speed and motion of all the cars around it. It uses all of that data to figure out not only how to drive the car but also to figure out and predict what potential drivers around the car are going to do. What’s impressive is that the car is processing almost a gigabyte a second of data.
Machine Learning vs Deep Learning: What’s the Difference?
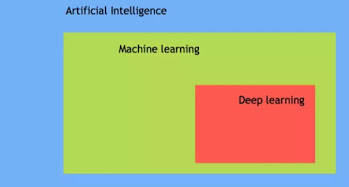
AI has three different levels:
- Narrow AI: A artificial intelligence is said to be narrow when the machine can perform a specific task better than a human. The current research of AI is here now
- General AI: An artificial intelligence reaches the general state when it can perform any intellectual task with the same accuracy level as a human would
- Active AI: An AI is active when it can beat humans in many tasks
What is ML?
Machine learning is the best tool so far to analyze, understand and identify a pattern in the data. One of the main ideas behind machine learning is that the computer can be trained to automate tasks that would be exhaustive or impossible for a human being. The clear breach from the traditional analysis is that machine learning can take decisions with minimal human intervention.
Machine learning uses data to feed an algorithm that can understand the relationship between the input and the output. When the machine finished learning, it can predict the value or the class of new data point.
What is Deep Learning?
Deep learning is a computer software that mimics the network of neurons in a brain. It is a subset of machine learning and is called deep learning because it makes use of deep neural networks. The machine uses different layers to learn from the data. The depth of the model is represented by the number of layers in the model. Deep learning is the new state of the art in term of AI. In deep learning, the learning phase is done through a neural network. A neural network is an architecture where the layers are stacked on top of each other
Machine Learning Process
Imagine you are meant to build a program that recognizes objects. To train the model, you will use a classifier. A classifier uses the features of an object to try identifying the class it belongs to.
In the example, the classifier will be trained to detect if the image is a:
- Bicycle
- Boat
- Car
- Plane
The four objects above are the class the classifier has to recognize. To construct a classifier, you need to have some data as input and assigns a label to it. The algorithm will take these data, find a pattern and then classify it in the corresponding class.
This task is called supervised learning. In supervised learning, the training data you feed to the algorithm includes a label.
Training an algorithm requires to follow a few standard steps:
- Collect the data
- Train the classifier
- Make predictions
The first step is necessary, choosing the right data will make the algorithm success or a failure. The data you choose to train the model is called a feature. In the object example, the features are the pixels of the images.
Each image is a row in the data while each pixel is a column. If your image is a 28×28 size, the dataset contains 784 columns (28×28). In the picture below, each picture has been transformed into a feature vector. The label tells the computer what object is in the image.
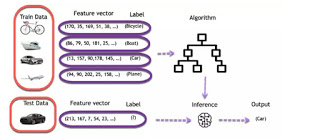
The objective is to use these training data to classify the type of object. The first step consists of creating the feature columns. Then, the second step involves choosing an algorithm to train the model. When the training is done, the model will predict what picture corresponds to what object.
After that, it is easy to use the model to predict new images. For each new image feeds into the model, the machine will predict the class it belongs to. For example, an entirely new image without a label is going through the model. For a human being, it is trivial to visualize the image as a car. The machine uses its previous knowledge to predict as well the image is a car.
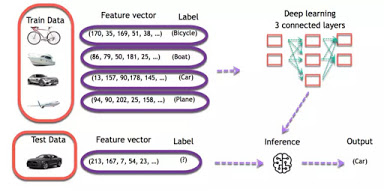
Deep Learning Process
In deep learning, the learning phase is done through a neural network. A neural network is an architecture where the layers are stacked on top of each other.
Consider the same image example above. The training set would be fed to a neural network
Each input goes into a neuron and is multiplied by a weight. The result of the multiplication flows to the next layer and become the input. This process is repeated for each layer of the network. The final layer is named the output layer; it provides an actual value for the regression task and a probability of each class for the classification task. The neural network uses a mathematical algorithm to update the weights of all the neurons. The neural network is fully trained when the value of the weights gives an output close to the reality. For instance, a well-trained neural network can recognize the object on a picture with higher accuracy than the traditional neural net.
Automate Feature Extraction using DL
A dataset can contain a dozen to hundreds of features. The system will learn from the relevance of these features. However, not all features are meaningful for the algorithm. A crucial part of machine learning is to find a relevant set of features to make the system learns something.
One way to perform this part in machine learning is to use feature extraction. Feature extraction combines existing features to create a more relevant set of features. It can be done with PCA, T-SNE or any other dimensionality reduction algorithms.
For example, an image processing, the practitioner needs to extract the feature manually in the image like the eyes, the nose, lips and so on. Those extracted features are feed to the classification model.
Deep learning solves this issue, especially for a convolutional neural network. The first layer of a neural network will learn small details from the picture; the next layers will combine the previous knowledge to make more complex information. In the convolutional neural network, the feature extraction is done with the use of the filter. The network applies a filter to the picture to see if there is a match, i.e., the shape of the feature is identical to a part of the image. If there is a match, the network will use this filter. The process of feature extraction is therefore done automatically.
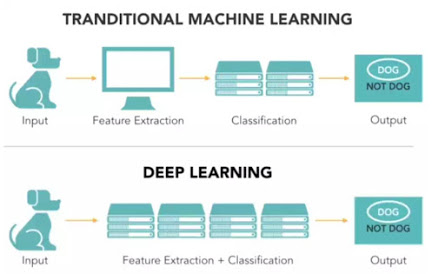
Difference between Machine Learning and Deep Learning
| Machine Learning | Deep Learning | |
| Data Dependencies | Excellent performances on a small/medium dataset | Excellent performance on a big dataset |
| Hardware dependencies | Work on a low-end machine. | Requires powerful machine, preferably with GPU: DL performs a significant amount of matrix multiplication |
| Feature engineering | Need to understand the features that represent the data | No need to understand the best feature that represents the data |
| Execution time | From few minutes to hours | Up to weeks. Neural Network needs to compute a significant number of weights |
| Interpretability | Some algorithms are easy to interpret (logistic, decision tree), some are almost impossible (SVM, XGBoost) | Difficult to impossible |
When to use ML or DL?
In the table below, we summarize the difference between machine learning and deep learning.
| Machine learning | Deep learning | |
| Training dataset | Small | Large |
| Choose features | Yes | No |
| Number of algorithms | Many | Few |
| Training time | Short | Long |
With machine learning, you need fewer data to train the algorithm than deep learning. Deep learning requires an extensive and diverse set of data to identify the underlying structure. Besides, machine learning provides a faster-trained model. Most advanced deep learning architecture can take days to a week to train. The advantage of deep learning over machine learning is it is highly accurate. You do not need to understand what features are the best representation of the data; the neural network learned how to select critical features. In machine learning, you need to choose for yourself what features to include in the model.
“The Machine Learning Life Cycle – 5 Challenges for DevOps”
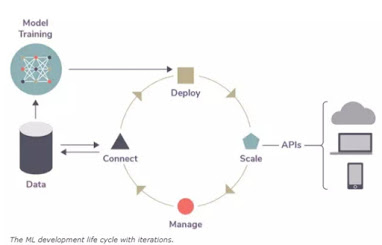
Machine learning is fundamentally different from traditional software development applications and requires its own, unique process: the ML development life cycle.
More and more companies are deciding to build their own, internal ML platforms and are starting down the road of the ML development life cycle. Doing so, however, is difficult and requires much coordination and careful planning. In the end, though, companies are able to control their own ML futures and keep their data secure.
After years of helping companies achieve this goal, we have identified five challenges every organization should keep in mind when they build infrastructure to support ML development.
Heterogeneity
Depending on the ML use case, a data scientist might choose to build a model in Python, R, or Scala and use an entirely different language for a second model. What’s more, within a given language, there are numerous frameworks and toolkits available. TensorFlow, PyTorch, and Scikit-learn all work with Python, but each is tuned for specific types of operations, and each outputs a slightly different type of model.
ML–enabled applications typically call on a pipeline of interconnected models, often written by different teams using different languages and frameworks.
Iteration
In machine learning, your code is only part of a larger ecosystem—the interaction of models with live, often unpredictable data. But interactions with new data can introduce model drift and affect accuracy, requiring constant model tuning and retraining.
As such, ML iterations are typically more frequent than traditional app development workflows, requiring a greater degree of agility from DevOps tools and staff for versioning and other operational processes. This can drastically increase work time needed to complete tasks.
Infrastructure
Machine learning is all about selecting the right tool for a given job. But selecting infrastructure for ML is a complicated endeavor, made so by a rapidly evolving stack of data science tools, a variety of processors available for ML workloads, and the number of advances in cloud-specific scaling and management.
To make an informed choice, you should first identify project scope and parameters. The model-training process, for example, typically involves multiple iterations of the following:
· an intensive compute cycle
· a fixed, inelastic load
· a single user
· concurrent experiments on a single model
After deployment and scale, ML models from several teams enter a shared production environment characterized by:
· short, unpredictable compute bursts
· elastic scaling
· many users calling many models simultaneously
Operations teams must be able to support both of these very different environments on an ongoing basis. Selecting an infrastructure that can handle both workloads would be a wise choice.
